Fine-Grained Controllable Text Generation Using Non-Residual Prompting (ACL2022)
本文针对传统的CLM(Casual language model(next token prediction))控制文本生成中引入condition出现的两个问题进行修正,使生成文本更好更灵活的受控。
两个问题
长距离依赖(Postional Variance)
![[animate output image]](/.com//ezgif-5-6e47d1f7eb.gif)
这个问题在于随着生成的context的越来越长,传统的CLM会较为平均的关注prompt tokens以及之前生成的context tokens从而使得后期生成的context tokens受prompt tokens越来越小
条件污染(Condition/Prompt pollution)

此问题在于,由于传统的CLM是将Prompt tokens作为prefix tokens的一部分输入给同一个text decoder,由于transformer的结构,那么generated token的embedding就会与prompt token的embedding由attention机制融合到一起,当模型在生成过程中如果需要转换prompt token,之前的prompt token由于已经与已生成的text token在embedding层面融合,所以没有办法在切换新prompt token后抹除旧prompt token对后续文本生成的影响,除非重新计算之前的text token与prompt的attention从而得到新的embedding(这样会带来更大的计算开销)
解决问题的两个手段

本文通过:
将Prompt token单独使用一个CLM进行处理,与负责生成context token的CLM进行解耦,从而部分程度缓解条件污染问题。
针对生成context token的CLM,让其拥有两组不同的embedding,两组embedding的生成方式不同,从而解决长距离依赖问题。
模型的工作流程

一个更加形象的例子为:

最后观察这一张图,prompt token的embedding是作为cross attention中的kv(待验证)与context token做cross attention,通过这种方式从而缓解长距离依赖的问题:
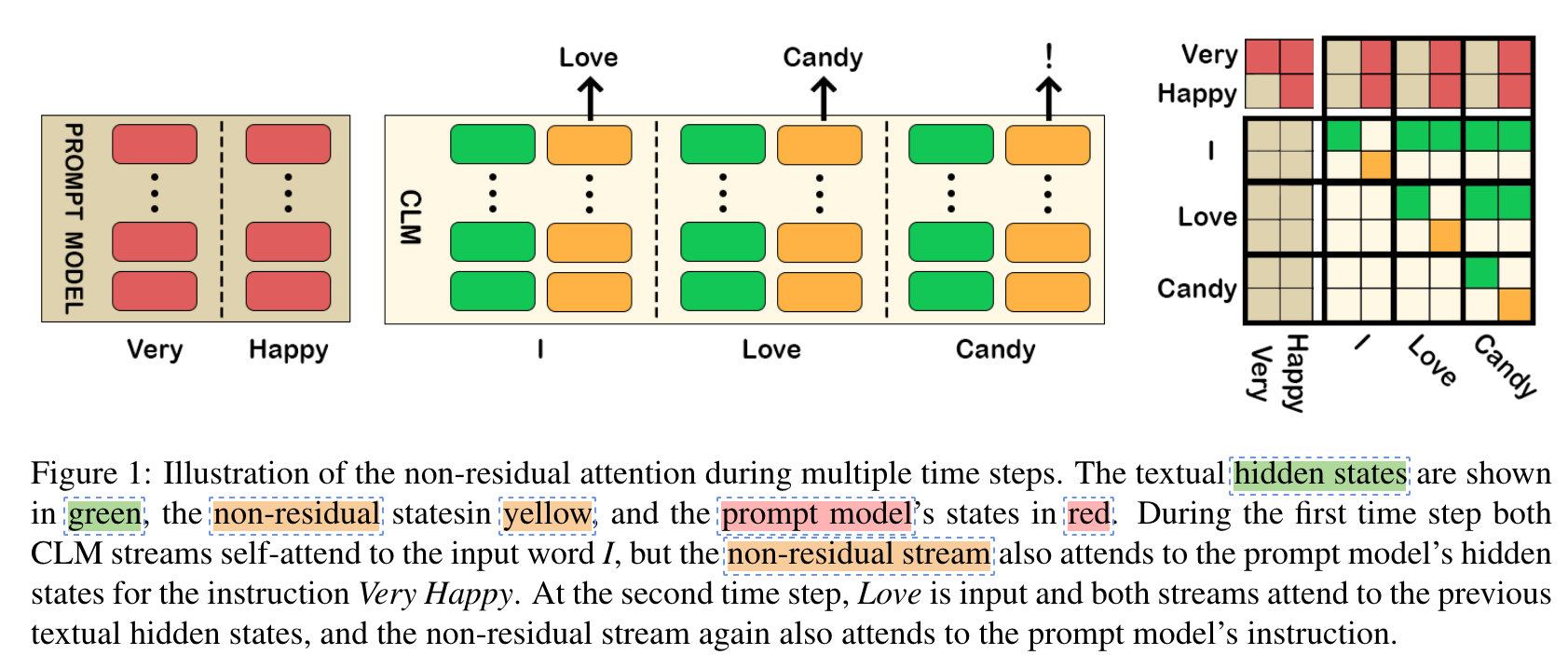
可以观察到:
- 在context CLM中,绿色的hidden states代表context stream,这一部分的生成只取决于context states之前的绿色的context hidden states而与红色的promt hidden states无关。
- 在context CLM中,黄色的hidden states(对应了gif动图中蓝色三角形)代表non-residual stream,这一部分hidden states与之前步中的绿色的context hidden states做fusion后作为query再与红色的prompt hidden states做cross attention,最终由这一部分作为预测下一个词的判据。
代码部分
这是其仓库地址: https://github.com/FreddeFrallan/Non-Residual-Prompting